Text of my presentation at the Library Connect webinar “Research data literacy and the library” December 8th 2016. Other presenters was Sarah Wright from Cornell University and Anita de Waard from Elsevier.
Hi all. Land line phones is like a vintage thing around here so I’m calling in from Copenhagen on a cell phone and I hope you will all be able to hear me clearly. I’m gonna be talking about how Copenhagen University Library is supporting data literacy among students and researchers. We started early 2016 by opening 3 physical data lab in 3 different faculty libraries. In my talk I will mainly focus on one of the data labs, Digital Social Science Lab, at The Faculty Library of Social Sciences.
But first I like to ask and answer the question “Why supporting data literacy at all?”. Basically what we are doing in at Copenhagen University Library is a reaction to some of the changes we have seen in higher education in recent years. I like to give you an example on those changes. When I did my master thesis back in 2007 I did interviews with relevant people to collect information and data on my field of interest; I had recorded the interviews, transcribed them and analyze what was said in them. That was my data and the way of handling it. Today students and researchers has other opportunities to explore the world. In Digital Social Science Lab we recently had a master student presenting how he harvested 2.5 million online articles on the crypto marked, analyzed them with a machine learning method called topic modeling and in the end visualized the huge amount of data in one single slide. There is only 9 years between the two papers but they hold a huge difference in the way scholars work. Both methods are valid today and we are not trying to say, that one way is better than the other – we are simply trying to show students and researcher that there are other opportunities today.
The amount of open data available to use in research and studies has exploded. It’s so massive it’s beyond our imagination. It’s good, it gives us new doors to open in order to explore the world, but to get the keys to those doors, to get a benefit of this development, academia need the tools, methods and skills to master it – otherwise the doors are closed. And that’s what we are trying to support in our data lab’s.
In general, I strongly believe, that when higher education and research are changing, libraries should look at themselves and see if it should take some sought of action – a library of status quo is not a good library – and our 3 data lab’s is a direct reaction to the changes we have seen at our University.
The 3 data lab’s is located at the Faculty Libraries at Humanities, Social Sciences and Natural- and Health Science. They don’t function as isolated islands but as a connected network where we coordinate events, staff training, license agreements and so on.
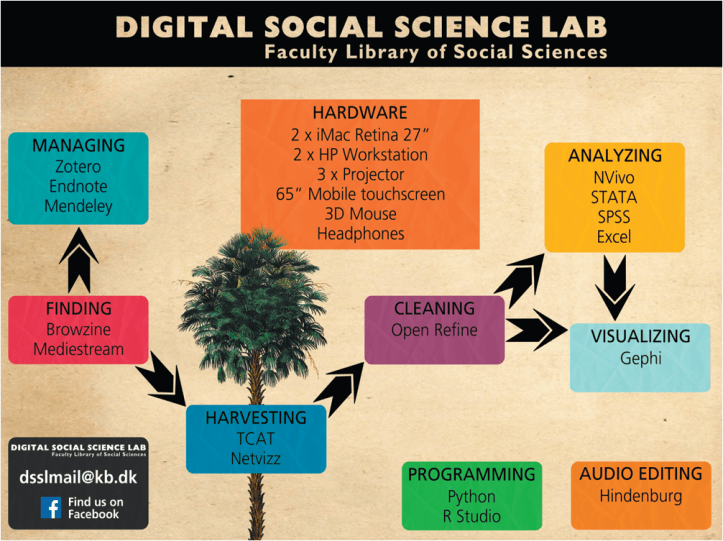
I will now move on to talk specific about one of the data labs and how it works. Digital Social Science Lab is an open platform for education and events on digital methods. It’s relevant hardware and software for harvesting, cleaning, analyzing and visualizing data and it’s a flexible and dynamic physical learning environment.
One of the key elements in Digital Social Science Lab is events and instructions on different tools and methods for data handling to empower academia with data literacy. The library has its own regular courses but what you see on the slide is a faculty member from sociology who is doing a talk on how he uses network analysis tools on various data sets. So in this case the library is not the expert, we facilitate that data savvy folks meet, talk and learn from each other. I get back to that in a second.

On our own part of training and instructions we are trying to cover the whole workflow of working with data: From harvesting, to cleaning, to analyzing and visualizing data. We try to capture both introduction and advanced level on all tools and we have chosen both very advanced and powerful programs like NVivo which takes time to master, and more intuitive and easy programs like TCAT and Netvizz to make sure people new to data handling, is not scared off. The list of software and programs are dynamic and we add new ones to the list over time.
Besides our own instructional program, we facilitated peer-to-peer sessions in the data lab. We have a series of events called Digital Methods Session where students come and present their work and experiences using digital methods in studies to fellow students. We also do data sprints where people bring datasets and collaborate on analyzing them. We find the facilitating approached really really strong because the library can’t cover everything and because we this way help building a community for data literacy where we bring people together interdisciplinary across the whole university. That’s really valuable for academia; we are not only providing skills, we are also building a network.
We discussed how important the physical space was in the beginning of the process. You could argue that the training could take place anywhere but we ended up using a fair amount of energy and resource on the physical lab. We believe that the physical setup surrounding us highly effects our ability to learn and collaborated. So we decided to build a data lab for people and not for machines – there is only 4 workstations in the lab and that’s actually enough because students bring their own laptop’s and they are often powerful enough to handle the amount of data we work with. Everything is on wheels in the lab and can be moved around to fit different settings for learning. We have worked together with a production designer to create a visual story of the lab and we choose a botanical theme, both because the library is located in the old botanical laboratory but also because botanical researchers has always been really keen on exploring the world and collect and preserve data in form of plants and we thought that story would fit god to a library data lab.

With the physical setup of the data lab we also want to create an alternative to the traditional learning setting on campus. The traditional learning situation in higher education is rows of people who are listening to a lecture. We’re created a dynamic and flexible space where stuff can be moved around to fit different kind of scenarios and that have had a huge attraction on students and faculty members.
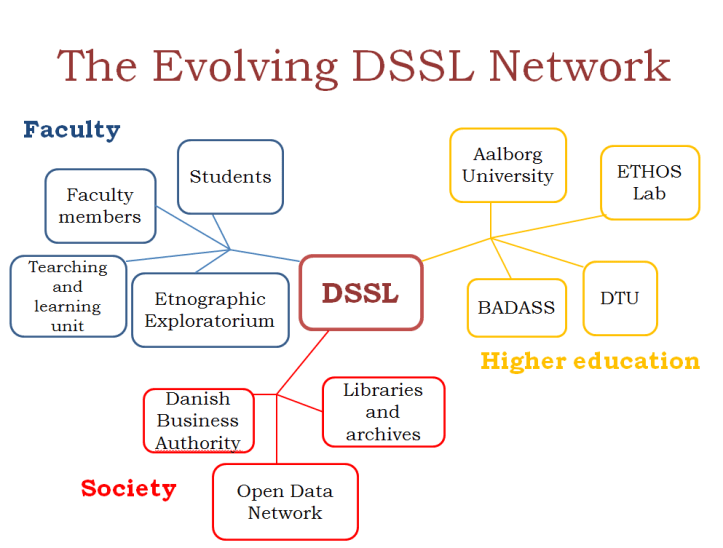
An important part of Digital Social Science Lab is the network and community we’re created around the lab. We both have internal and external partners who we collaborate with on events, workshops and sharing of ideas. We want to break down the silos between academic institutions because we think that scholars across intuitions and disciplines can learn a lot from each other.
If I should point to one key to success and impact in this area, it’s coffee. We have used a year of coffee drinking with students, faculty members and management. We have been presenting the basic idea of Digital Social Science Lab and gotten a lot of feedback. With the countless coffee appointments we have both created a solid base of knowledge on how to do this, but also a network and an ownership on the things we have been doing. People wanted to use Digital Social Science Lab before we even opened it.
I thought it might be interesting for you to hear a little about some of the challenges in the process of making Digital Social Science Lab. Two questions we have heard a lot doing the coffee drinking with students and faculty members is:
“Is this really a library task?”
And
“If you do this, is it on the benefit of something else?”
Man people have a fairly traditional idea of what a library is, and they are luckily very happy about the core services of the academic library. But the library of today might not fit the reality of tomorrow, so we need to be a head of the changes that takes place in research and higher education and also be clear about this to the academic community.
Skill development had been going great but had the potential to be some sought of an obstacle. Some of the programs we work with is a bit aside from the regular library tasks and skills, so we have used a fair amount of time looking at the different programs and making skill development plans for each of them. The most important asset of Digital Social Science Lab is not the hardware or software but the people who connects the dots and it’s crucial that they got the right training and skills to carry out the job.
When you do something radical new I think it’s important that you think about how you talk about it to stakeholders and users. So we have used some time developing our story and get answers to “what we are doing” and “why it is important”. That has been really helpful in all the coffee drinking. We have been able to clearly explain what we plan to do and why.
That also has something to do with how the library position itself in the academic environment. We are moving into new land here and it’s been important for us, that no teachers has been thinking “what on earth are the library doing – it’s my job to teach SPSS”
What we’re learned doing the process is, that it’s absolutely not enough just to fill a room with hardware and software for working with data. It takes skills and facilitation from the library to bridge students and researchers with data literacy.
Skill development is crucial to support data literacy and it needs lots of planning and time.
The facilitating role for the library, bringing people together and building a community around data literacy, is a very strong position to take
In that sense network is key. Get on with the coffee drinking.
And then we found that the support of data literacy doesn’t fit all subjects the same way. We had a huge impact with this in Humanities and social Sciences but we are not having the same breakthrough with natural- and health science. That might has something to do with local context but we also find it hard to make a fit and find the right role for the library because the community of natural and health scholars has been working with data for a long time.
That’s it. Thanks for listening.


