– Written by Library Lab Fellow Knut Anton Bøckman, library system consultant at The Royal Library, Copenhagen
Linked Open Data (LOD) is a method for making structured data more useful on the web. I thank Library Lab Blog Boss Christian for the opportunity to use this post to give a few reasons why libraries should care about it. Since I work with The Royal Library’s discovery system, REX, my main focus is on how libraries can use LOD to improve the discoverability of their collections. In a later post at The Library Lab, I’ll get to how this is done in a project at The Royal Library.
The mechanics of LOD
Data get more useful on the web when they are open and interoperable. Open data in this case are not only web accessible, but also reusable, i.e. the data must be Public Domain (CC0), or CC-BY or CC-BY-SA. For library metadata, i.e. the stuff that makes up catalogue records, this is often straightforward (The Royal Library metadata is CC0).
To be web interoperable the data need to be machine readable. This is the trickier part. Humans read texts very well because we infer meaning of words from the context they’re in. So if we search a library database and find this record..
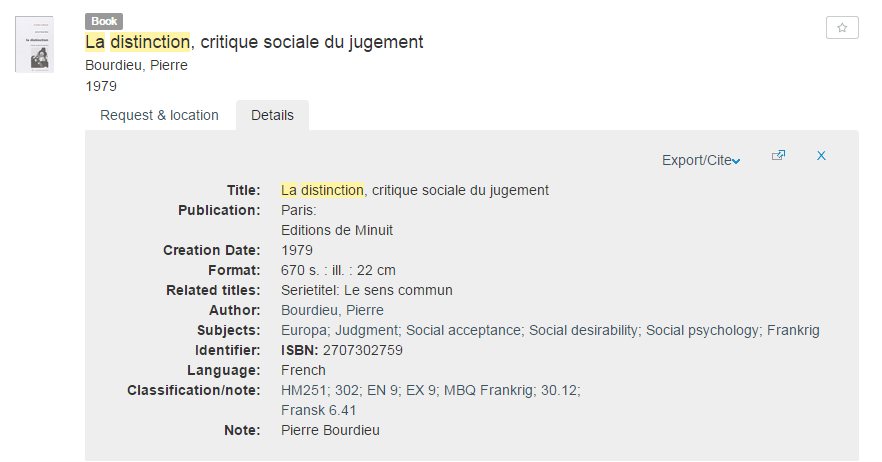
… we know that Pierre Bourdieu is the person that wrote a book called La Distinction, because his name is mentioned as Author on the record for this book. We also know a whole lot of other things just from looking at this record, because we are able to infer from context.
Computers, however, need this spelled out much more clearly – which first of all means breaking the catalogue record document down into simple propositional statements, e.g.: “Pierre Bourdieu has written La Distinction”
This is a simple statement of a relation (“has written”) between a subject (Bourdieu) and an object (La distinction). In order for a machine to infer from this, e.g. in order to find other other books written by the same person, we need to explain this context. This is done by providing links that uniquely identify the data elements and the relation between them. So the sentence above can be restated as a triple of links:
http://id.loc.gov/authorities/names/n79018166.html
http://purl.org/dc/elements/1.1/creator
http://viaf.org/viaf/258248470/
Try it yourself – this triple restates the sentence using unique identifiers (URIs), over the http protocol, it provides useful information and links to further discoverability. Thus, it complies with the principles for linked data set forth by Tim Berners-Lee.
True, this is only one simple statement out of many from the catalogue record document. Having the same for all (or all relevant) data in all catalogue records means a lot of triples for the computer to run through (in REX you search hundreds of millions of records). The great thing with computers is that they’re really good at such repetitive tasks. (Humans are not and make up for it by being really good at contextual understanding). But how about creating these statements from the text-based catalogue records we now have? Since library data is fairly structured and standardized, and since the library world is no stranger to the use of authority files (like the ones used for linking above), this can be automated to a very high degree. Still, there is significant work involved, and in a subsequent post, I’ll describe how we are starting work on this at The Royal Library. For now, I’ll turn to why doing so is important to libraries.
Why LOD in Libraries?
Libraries were information hubs avant le mot. They should be uniquely positioned to prominence in a society whose fabric is increasingly permeated by demands for and production of information. The social transformation has come about through information turning digital, of course, but in fact libraries were pioneers in this process, too. It started long before the last decade’s surge in digitization of special collections and in acquisition of e-books and e-journals. The infrastructure of their knowledge base, the catalogues, by which you can search library holdings and get access to resources that fulfill you information need went digital decades ago, and have been made available through the web since web began. And to boot, use of a library’s resources are free (or more correctly: already paid for) to the community it serves.
In spite of all this, library resources are not easily discoverable on the web. True, you can go to a library’s discovery site, like REX for the Royal Library, and search for your stuff. Notice that you first need to find out where to go before you can start finding out what you want to know. This is suboptimal in a web based society, meaning libraries lose potential patrons and, more importantly, people’s information needs are not met as efficiently as they could. Optimally, doing a web search should provide you with information from your local library. Why is this not happening, even though libraries have web sites and their catalogues and discovery sites are on the web?
One reason is the difference often alluded to between being on the web and being of the web. While this slogan has a range of meanings, suffice it here to note that being of the web means exploiting standard tools of web interoperability to create knowledge in a distributed system. This distributed system is the web, and the distribution is performed by the web’s key element, the link, that connects one piece of information to another. Library catalogues, on the contrary, are isolated knowledge systems available on the web, but they are not web interoperable. They are silos. The last 7-8 years have seen the gradual integration of more databases into one discovery system – like in REX. So these silos are getting bigger and presumably serve their users better with one as opposed to hundreds of user interfaces – but they are still silos.
Hold on, you say, aren’t there lots of links in library catalogues? There are, but have a look and you’ll see these are mostly links to internal functions in the catalogue, such as performing a new search on an author’s name from a record, or making a request for an item. (Additionally, there are links to documents retrieved through search, of course.)
OK, but if we just publish all our catalogue records on the web, they’ll be indexed by web crawlers, and so retrievable by regular search engines, sending users to our catalogue, right? This is one option and many libraries do this, but it is not very efficient. The main reason is that every record will be indexed as a web document, and search engines tend to prefer web documents that other highly rated documents link to – this is not often the case with catalogue records. Moreover, the bare textual content of a typical catalogue record does not give the search engine much other information to determine whether it will be of relevance to its user – and this is the search engine’s main objective. (There is a whole Search Engine Optimization industry built around this, which I’ll not get into.)
What we need instead is for the elements of the library catalogue itself to be linked, so a web search engine would know what the elements are and what role they play, and from this are able to infer their usefulness to search engine users. This kind of inference requires, among other things, that the elements are uniquely identified, and that the links between elements are uniquely identified, and that their meaning is expressed in a shared, machine-readable vocabulary. It means increasing the semantic meaning of the web. It means giving search engines meaningful links to follow, instead of just text strings to index. It also requires that the elements are made openly available on the web – and that the links link data elements (like a person or a place), not whole documents (like a catalogue record) to each other. Improved discoverability is one major promise of linked open data for libraries.
To be continued..

LOD – the graffiti way


[…] Artiklen bygger på en tidligere blogpost. […]
LikeLike